Experience Based Coverage
Davide Bertalero
Davide Bertalero
Autonomous robots deployed long-term in human-centric indoor environments need to periodically remap them due to their high dynamism. Typically, robots start each run from scratch and without considering any type of prior knowledge that can be inferred by the previous runs. In this thesis, we propose a method to exploit the maps collected over time to aggregate the experience of the robot to extract a coverage path to efficiently re-explore the environment. The path, which is computed offline, ensures faster exploration, preventing robot failures.
We consider a robot equipped with a 2D LIDAR tasked to map a semi-static indoor environment such as a house or an office. Such an environment contains static elements (such as walls), semi-static objects that can change position but not during mapping (such as chairs), and other appearing semi-static obstacles initially not present inside the environment. The robot uses classical exploration techniques (such as frontier-based exploration) to acquire a sequence of maps of the same environment in different configurations (i.e., moving objects change locations) that are then used to speed up the mapping process.
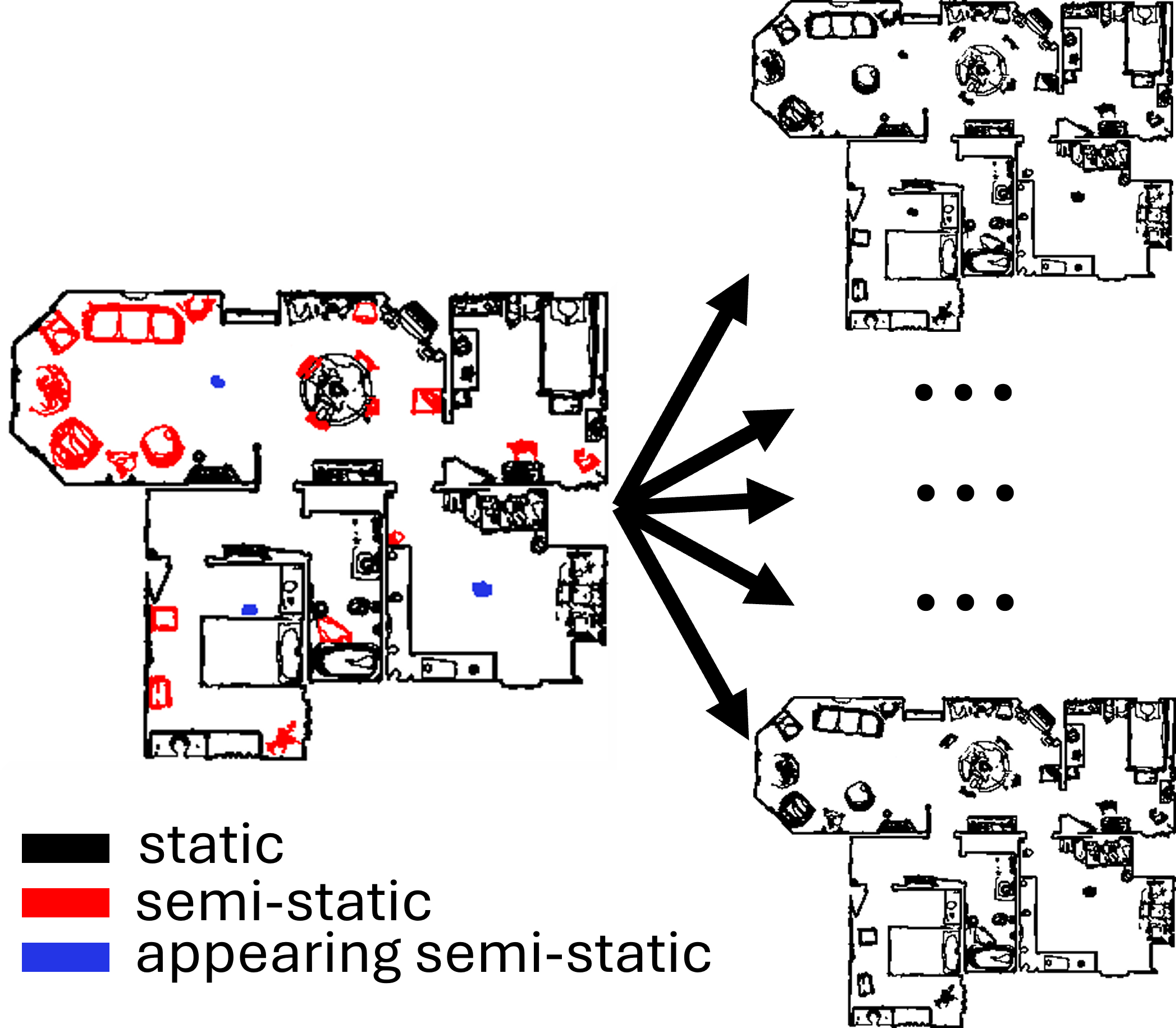
Dynamic environment example that showcases the different types of obstacles. Static elements are in black, semi-static objects are in red, while appearing obstacles are in blue.
The method we propose aggregates multiple maps collected in the same environment in different configurations, obtaining a cost map in which each cell encodes the occupancy probability of the corresponding sub-portion of the environment. After that, we apply a threshold to the aggregated cost map, obtaining a binary map in which each cell is marked as "free" or "occupied", and we extract a sequence of points in the boundaries of the free space (the blue points in the image). Then, we discretize the free space (red points in the image) and we use mathematical optimization to extract a subset of positions from which the robot can perceive most of the blue points, thus ensuring coverage of the environment. Finally, we compute a min-cost path to be executed by the robot to reach all the extracted positions.

A general overview of our method. (a) The sequence of maps collected inside the same environment with different configurations. (b) The cost map obtained by aggregating all the maps. (c) The possible positions the robot can reach (red points) to perceive the locations in the boundaries of the free space (blue points). (d) The optimal subset of locations selected by our algorithm and the optimal path to reach them.
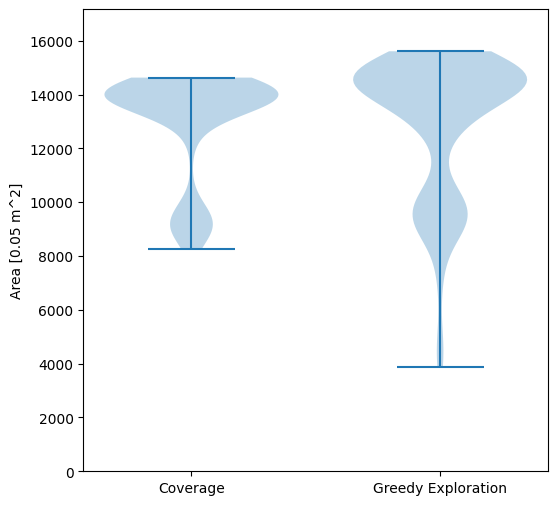
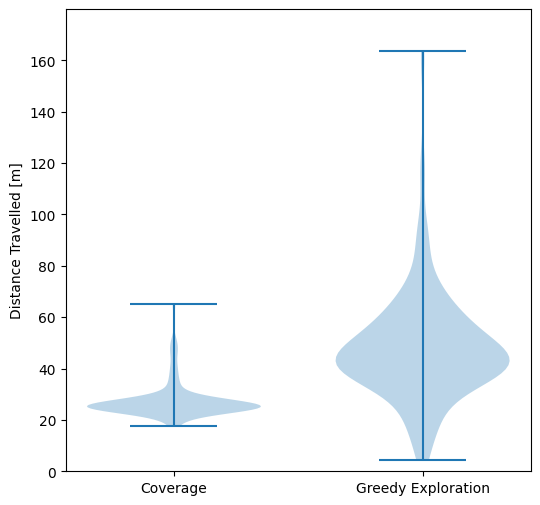
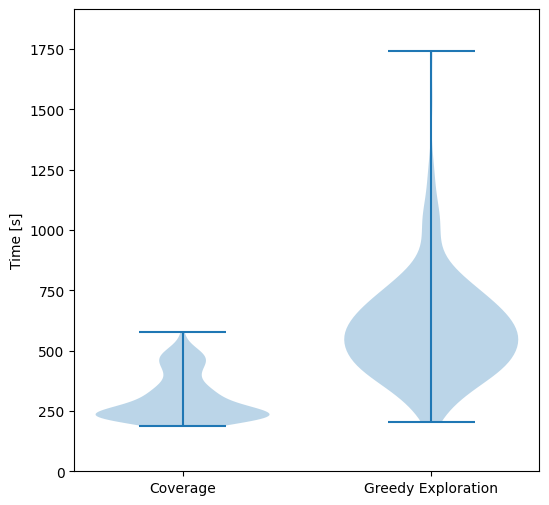
We tested this approach against the greedy frontier-based exploration strategy in simulation (using Stage). We generated 100 variants of the same environment with different obstacle configurations, and we run exploration and coverage for each of them. The results show that the exploration path extracted by our algorithm improves the exploration activity by reducing the travelled distance and the time to carry out the task.