Privacy-Preserving Robotic Perception for Object Detection in Curious Cloud Robotics
Michele Antonazzi, Matteo Alberti, Alex Bassot, Matteo Luperto, Nicola Basilico
Michele Antonazzi, Matteo Alberti, Alex Bassot, Matteo Luperto, Nicola Basilico
Cloud robotics allows low-power robots to perform computationally intensive inference tasks by offloading them to the cloud, raising privacy concerns when transmitting sensitive images. Although end-to-end encryption secures data in transit, it doesn't prevent misuse by inquisitive third-party services since data must be decrypted for processing. This paper tackles these privacy issues in cloud-based object detection tasks for service robots. We propose a co-trained encoder-decoder architecture that retains only task-specific features while obfuscating sensitive information, utilizing a novel weak loss mechanism with proposal selection for privacy preservation. A theoretical analysis of the problem is provided, along with an evaluation of the trade-off between detection accuracy and privacy preservation through extensive experiments on public datasets and a real robot.
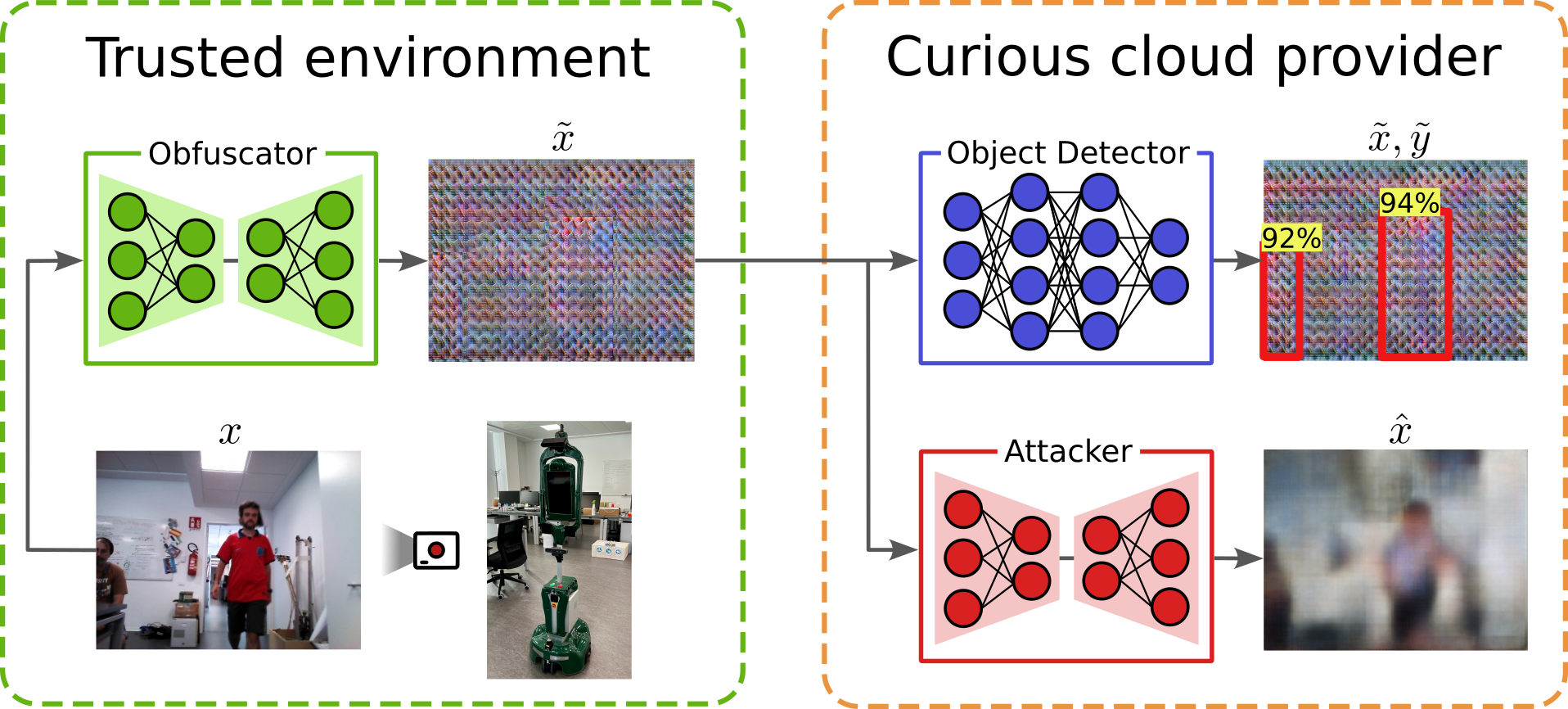
We consider a cloud robotic architecture in which a service robot leverages a third-party inference service for object detection. The robot performs queries to the remote neural network (called TaskNet) sending its visual perceptions that are remotely processed to detect object. In such a context, data protection is a major issue as privacy-sensitive data, that need to be decrypted for inference, could be used for malicious purposes by a potentially curious cloud provider. To solve this, we propose to add an encoder-decoder obfuscator to remove sensitive information while maintaining the necessary features to perform object detection from remote. We test our approach by implementing an attacker which aims to reconstruct the original input after obfuscation.
In the paper we theoretically and empirically prove that detection and privacy are competing task. On the one hand, training the encoder-decoder with a large bottleneck ensures good detection but low privacy. This is because the proposal-based object detector force the encoder-decoder to reconstruct the original input to produce the same activation over the thousand proposals optimized in the loss function. On the other hand, compressing the bottleneck enhance privacy but degrades the task performance (see the paper for more details). To address this, we propose a co-training scheme to obtain both detection and privacy. It consists of training the encoder-decoder with a "weakened" task loss calculated using a (very) limited but meaningful subset of proposals. This approach forces the encoder-decoder (even with a large bottleneck) to extract from the input only the essential features to activate a small but targeted subset of TaskNet proposals, while discarding those features exploitable by potential attackers for reconstructing the original input from its obfuscated version. For each ground truth, our algorithm divides the proposal into two sets: positives and negatives. Positive proposal well overlap their corresponding ground truth and need to be optimized during training. On the contrary, negative proposals are bounding box on the background with a high confidence that must be suppressed to reduce errors. Our algorithm selects a fixed number of proposals (both positive and negative) that are used by the TaskNet loss function to train the encoder-decoder.
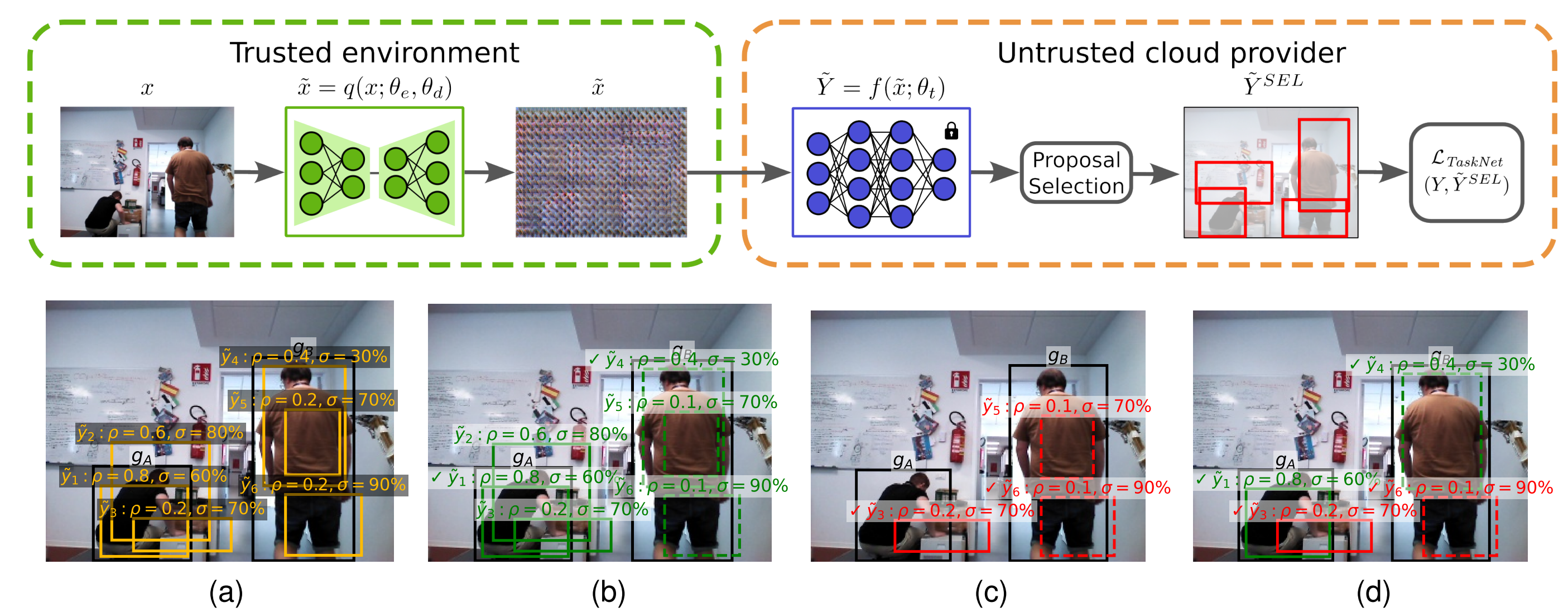
Our co-training scheme for detection and privacy. (First row) Given an image \(x\) and the ground truth bounding boxes \(Y\), the encoder-decoder obfuscator is trained using the loss function of the TaskNet (whose weights are frozen) calculated between \(Y\) and a subset (\(\tilde{Y}^{SEL}\)) of the proposals produced by the TaskNet on obfuscated images \(\tilde{x}\). (Second row) An example of the proposal selection procedure applied on a perception acquired by our Giraff-X robot. (a) The GT bounding boxes \(g_A\) and \(g_B\) (in black) and some proposals from the TaskNet's dense set (in orange). Note that, for visualization purposes, we depict only a few proposals among the thousands produced by the TaskNet, many of which overlap and have low confidence and IoU. (b) Positive proposals matched with \(g_A\) (in green) and \(g_B\) (in dashed green); the selected proposals are marked with a \(\checkmark\). (c) Negative proposals associated with \(g_A\) (in red) and \(g_B\) (in dashed red) with \(\bar{\rho} = 0.5\). (d) The final \(\tilde{Y}^{\text{SEL}}\) when \(p=n=1\).
We conduct an extensive experimental campaign to validate our approach using publicly available datasets for object detection. We train the TaskNet (a Faster R-CNN) and the encoder-decoder obfuscator using COCO. Then, we perform tasting using COCO and Pascal VOC to show that out approach is effective also in out-of-distribution settings. For the evaluation, we consider the tasks of people and vehicle detection, two scenarios with strong privacy-preservation requirements. Additionally, we test our approach with data from our real robot (a GIRAFF-X) navigating in our laboratory.
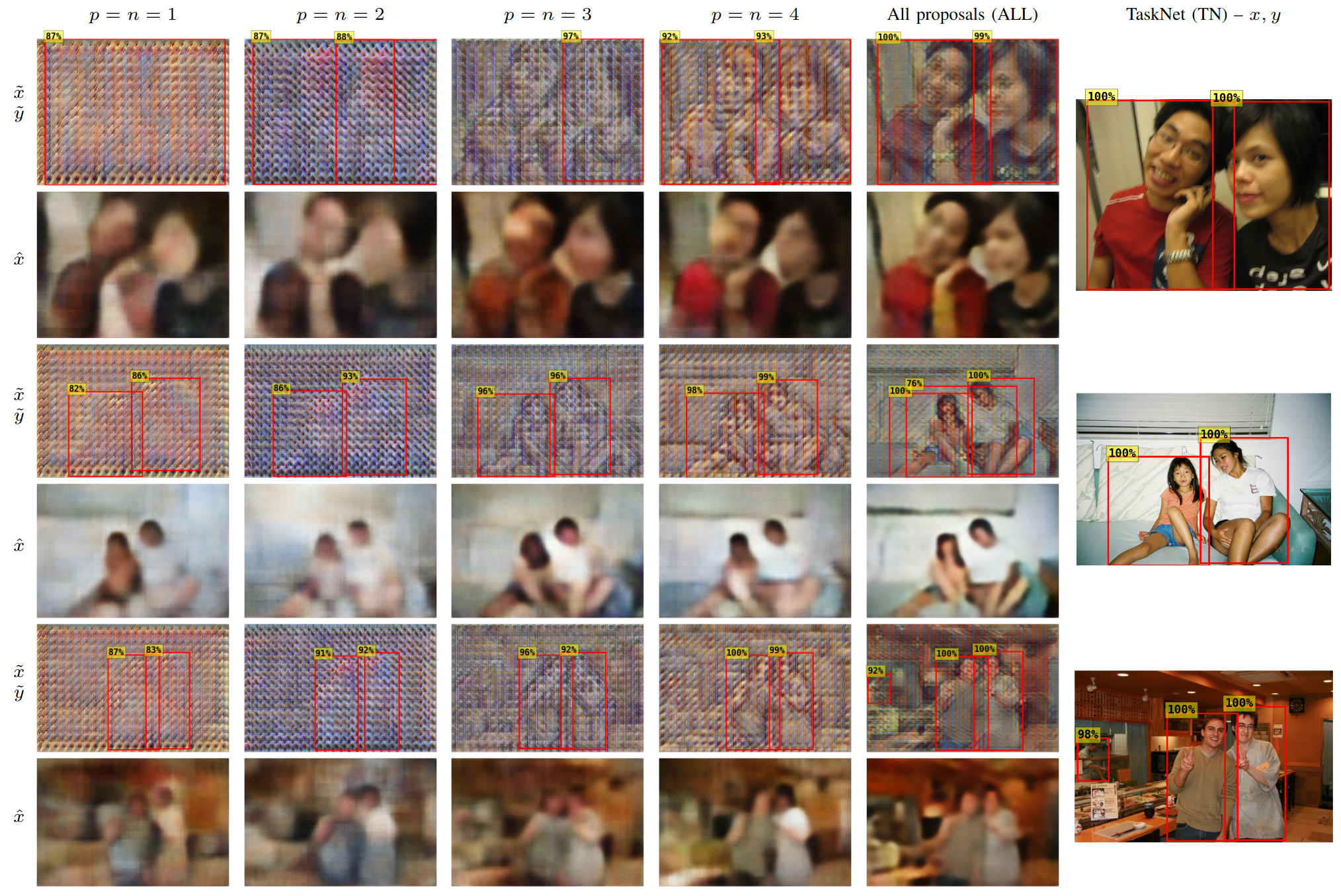
People Detection - Examples of our method applied on out-of-distribution examples from Pascal VOC 2012. (Left) Obfuscated images and their reconstructions by the attacker. (Right) Plain images and TaskNet detections for reference. The red bounding boxes are the TaskNet's detections with \(\sigma(y), \sigma(\tilde{y}) \geq 0.75\) and filtered by Non-Maximum Suppression (NMS) with IoU threshold of 0.5.
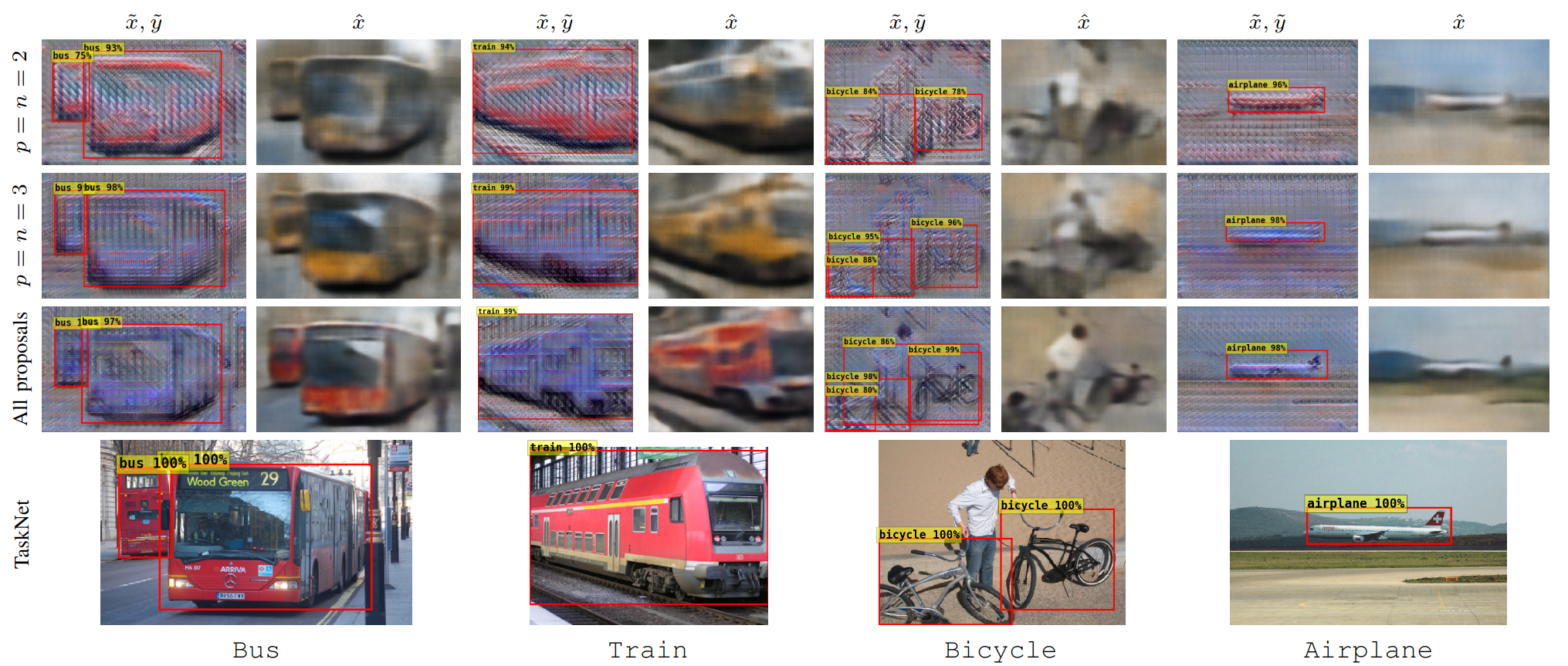
Vehicle Detection - Examples of our method applied on out-of-distribution examples from Pascal VOC 2012. (Top) Obfuscated images and their reconstructions by the attacker. (Bottom) Plain images and TaskNet detections for reference. The red bounding boxes are the TaskNet's detections with \(\sigma(y), \sigma(\tilde{y}) \geq 0.75\) and filtered by Non-Maximum Suppression (NMS) with IoU threshold of 0.5.

Data from a real robot performing People Detection - Examples of our method applied on out-of-distribution data from our real robot. (Left) Obfuscated images and their reconstructions by the attacker. (Right) Plain images and TaskNet detections for reference. The red bounding boxes are the TaskNet's detections with \(\sigma(y), \sigma(\tilde{y}) \geq 0.75\) and filtered by Non-Maximum Suppression (NMS) with IoU threshold of 0.5.
@misc{comingsoon}