Instance-Guided Unsupervised Domain Adaptation for Robotic Semantic Segmentation
Michele Antonazzi, Lorenzo Signorelli, Matteo Luperto, Nicola Basilico
Michele Antonazzi, Lorenzo Signorelli, Matteo Luperto, Nicola Basilico
Semantic segmentation networks, which are essential for robotic perception, often suffer from performance degradation when the visual distribution of the deployment environment differs from that of the source dataset on which they were trained. Unsupervised Domain Adaptation (UDA) addresses this challenge by adapting the network to the robot’s target environment without external supervision, leveraging the large amounts of data a robot might naturally collect during long-term operation. In such settings, UDA methods can exploit multi-view consistency across the environment’s map to fine-tune the model in an unsupervised fashion and mitigate domain shift. However, these approaches remain sensitive to cross-view instance-level inconsistencies. In this work, we propose a method that starts from a volumetric 3D map to generate multi-view consistent pseudo-labels. We then refine these labels using the zero-shot instance segmentation capabilities of a foundation model, enforcing instance-level coherence. The refined annotations serve as supervision for self-supervised fine-tuning, enabling the robot to adapt its perception system at deployment time. Experiments on real-world data demonstrate that our approach consistently improves performance over state-of-the-art UDA baselines based on multi-view consistency, without requiring any ground-truth labels in the target domain.
Semantic segmentation is a key component of robotic vision, as it enables autonomous systems to interpret complex environments and reason about object categories at the pixel level. Typically, segmentation models are trained on source datasets collected under controlled conditions, but their performance degrades when deployed in target environments characterized by different, though related, data distributions. This phenomenon, known as domain shift, is particularly critical for mobile robots, which must operate for long periods in previously unseen environments where annotated data are unavailable at training time and prohibitively expensive to acquire during deployment. Unsupervised Domain Adaptation (UDA) addresses the challenge of adapting a model to a new environment without relying on ground-truth labels or humans in the loop. An enstablished approach for UDA is the multi-view consistency method, where pseudo-labels are aggregated in a 3D environmental representation to enforcing spatial consistency. In this work, we propose an additional instance refinement step using SAM 2 to further improve the view-consistent pseudo-labels that present visual artifacts generated by the rendering process and, more importantly, fail to be instance-coherent as multiple categories are assigned to the same object.

Examples of the improvement provided by our method (third column) to the view-consistent pseudo-labels (middle column).
The goal of our method is to adapt a neural network for semantic segmentation \(f_{\theta_s}^{seg}\) pre-trained on a source dataset \(\mathcal{S}\) to a new and previously unseen target environment \(t\). We achieve this in the challenging settings where no ground-truth labels are available but only a sequence \(\mathcal{T}\) of \(N\) measurements acquired in \(t\), that combines RGB images \(\mathbf{I}^t\) and depth information \(\mathbf{D}^t\) localized in the environment by camera extrinsic \(\mathbf{H}^t\). At first, our proposed pipeline aggregates the model's predictions \(\mathbf{Y}^*\) in a volumetric map of the environment, which is used to render multi-view consistent pseudo-labels \(\mathbf{Y}^\texttt{MC}\) from each pose \(\mathbf{H}^t\). Then, the resulting annotations are further refined leveraging a foundation model for instance segmentation (SAM 2) that extracts object instances \(B_n\) from an image \(I_n\), that are coherent with a sequence of prompts \(P_n\). The object instances are filled with the object classes of \(Y_n^\texttt{MC}\) and aggregated in a new annotation \(Y_n^{\texttt{IR}}\). The final instance-coherent pseudo-labels \(\mathbf{Y}^\texttt{IR}\) are used to fine-tune the source model for the target environment \(t\), obtaining \(f_{\theta_t}^{seg}\).
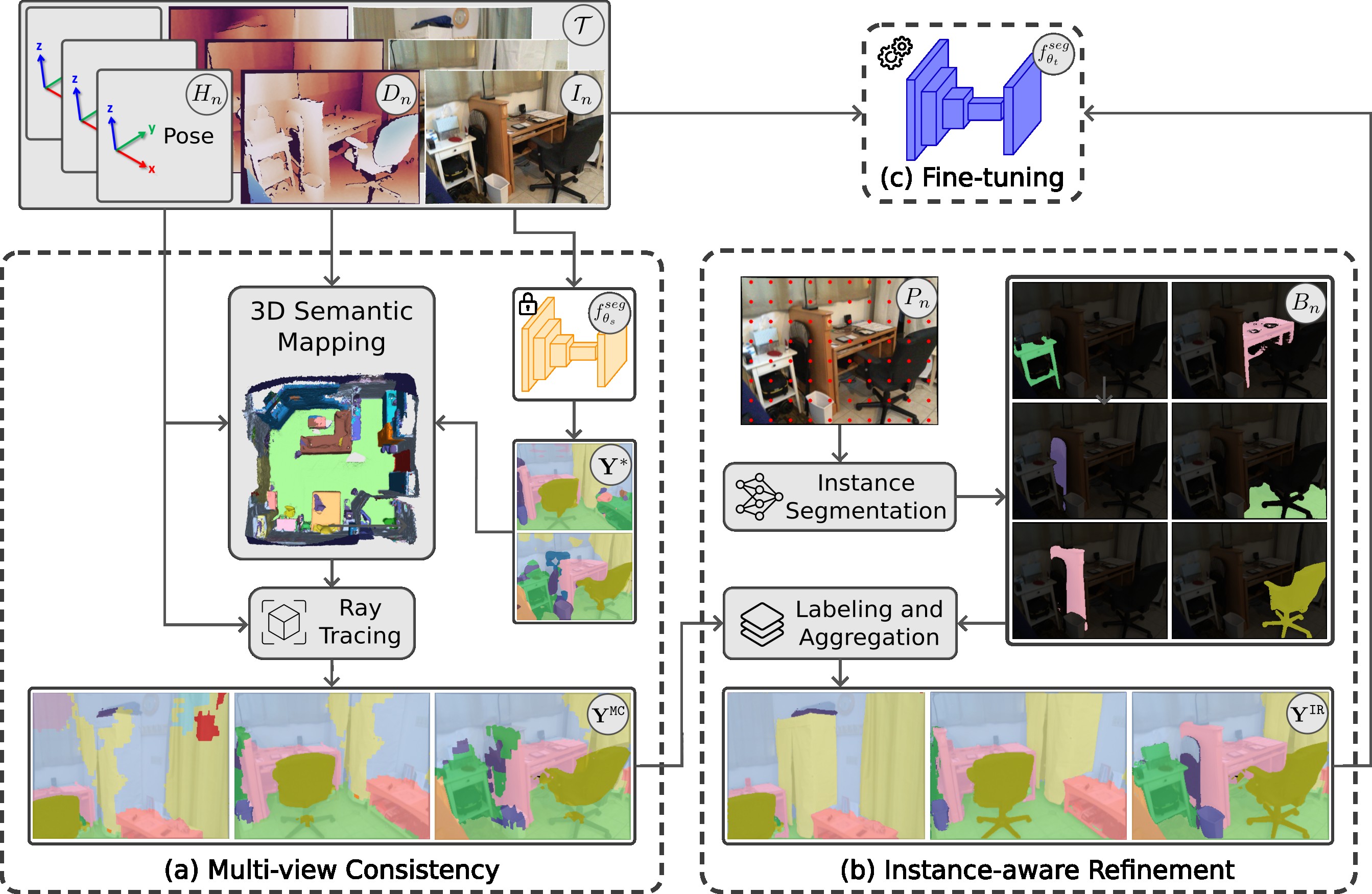
Our method (a) first aggregates the source model's predictions \(\mathbf{Y}^*\) into a 3D map to obtain multi-view consistent pseudo-labels \(\mathbf{Y}^\texttt{MC}\). (b) These are then refined with a foundation model for instance segmentation. (c) The resulting pseudo-labels \(\mathbf{Y}^\texttt{IR}\) are finally used to fine-tune the source model.
We perform an extensive experimental campaing using the Scannet dataset. We pre-train a DeepLabV3 architecture using the environments from 11 to 707 (source domain) and we use the scenes from 1 to 10 for adaptation (target domains). We consider the pre-trained model (PT) and the multi-view consistency (MC) as our baselines. We compare our methods using different prompting strategies: grid (\(\text{IR}_{\texttt{G}}\)), informed \(\text{IR}_{\texttt{I}}\), and a combination of the two \(\text{IR}_{\texttt{IG}}\).
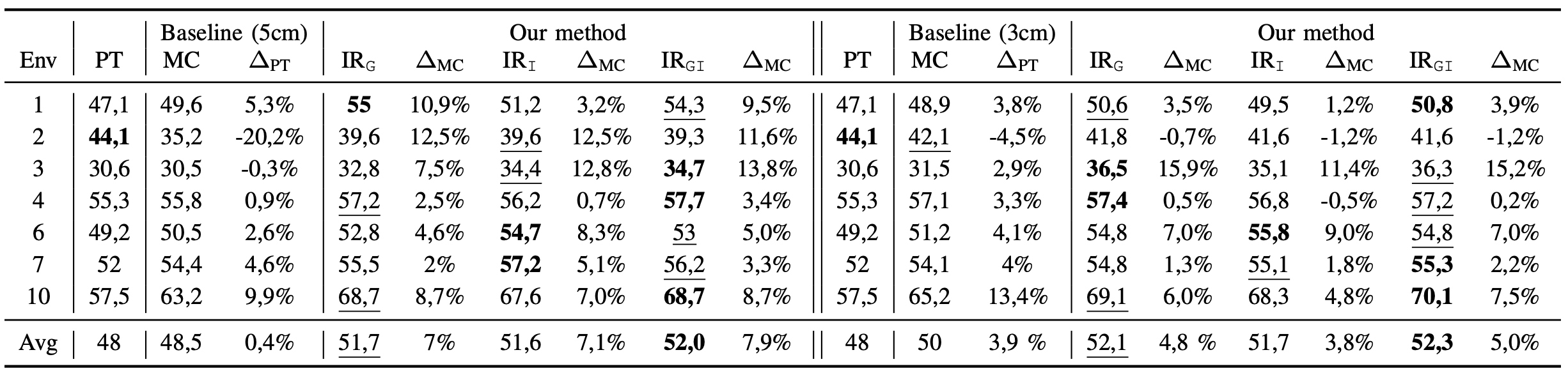
mIoU (best and second best values) of \(f_{\theta_t}^{seg}\) trained with our method (\(\text{IR}_{\texttt{I}}\), \(\text{IR}_{\texttt{G}}\), \(\text{IR}_{\texttt{IG}}\)) against the baseline (MC), and the pre-trained model (PT). Training and testing are performed using different sequences of the same environment.
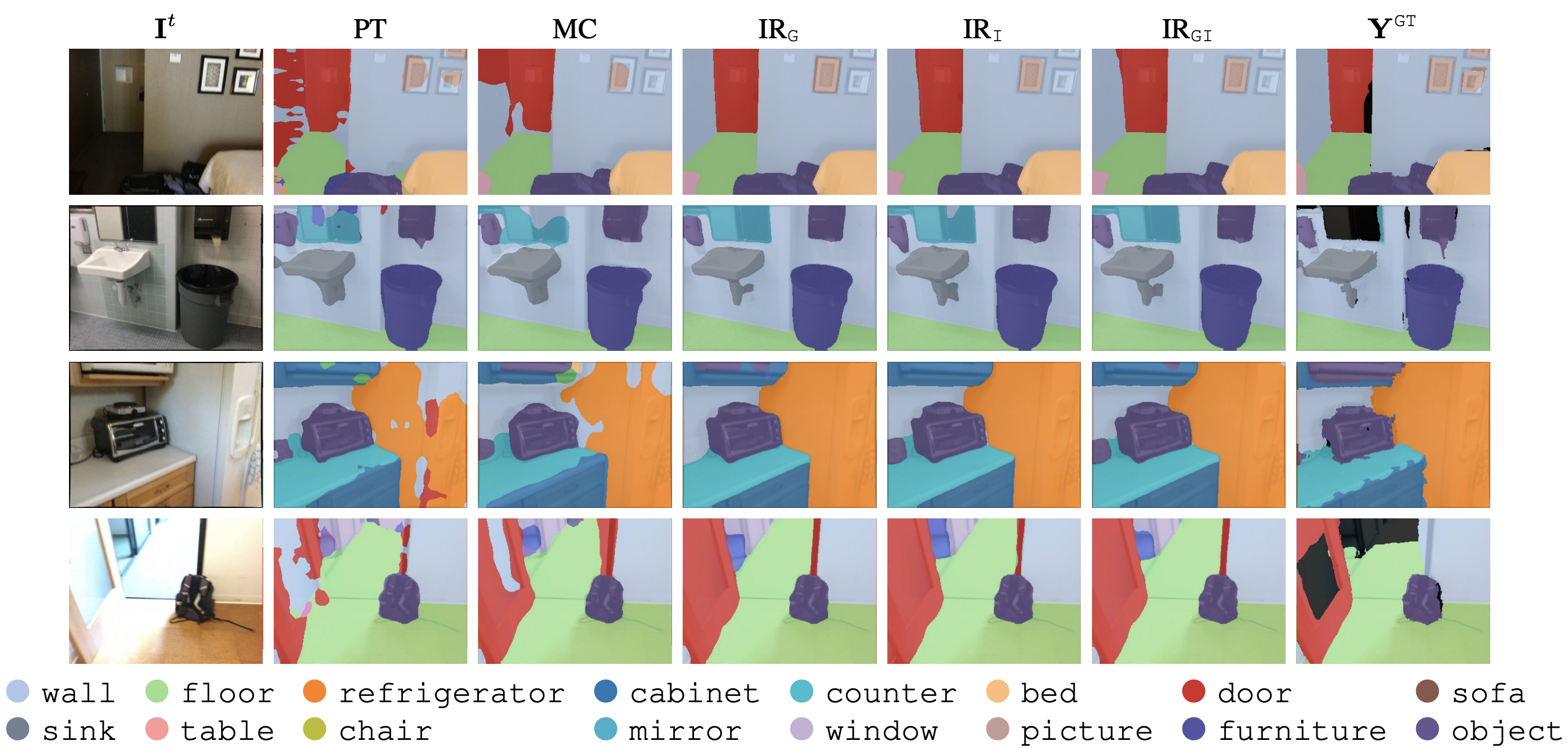
Segmentation improvements with different prompting strategies (\(\text{IR}_{\texttt{I}}\), \(\text{IR}_{\texttt{G}}\), \(\text{IR}_{\texttt{IG}}\)) compared to the baselines (MC and PT). The first two rows use a 5cm voxel size, the last two a 3cm. \(\mathbf{I}^t\) and \(\mathbf{Y}^\texttt{GT}\) denote the RGB images and ground-truth annotations. Black areas in \(\mathbf{Y}^\texttt{GT}\) are due to rendering errors or missing labels; these segmentation errors are improved by our IR.