Development and Adaptation of Robotic Vision in the Real-World: the Challenge of Door Detection
Michele Antonazzi, Matteo Luperto, N. Alberto Borghese, Nicola Basilico
Michele Antonazzi, Matteo Luperto, N. Alberto Borghese, Nicola Basilico
Mobile service robots are increasingly prevalent in human-centric, real-world domains, operating autonomously in unconstrained indoor environments. In such a context, robotic vision plays a central role in enabling service robots to perceive high-level environmental features from visual observations. Despite the data-driven approaches based on deep learning push the boundaries of vision systems, applying these techniques to real-world robotic scenarios presents unique methodological challenges. Traditional models fail to represent the challenging perception constraints typical of service robots and must be adapted for the specific environment where robots finally operate. We propose a method leveraging photorealistic simulations that balances data quality and acquisition costs for synthesizing visual datasets from the robot perspective used to train deep architectures. Then, we show the benefits in qualifying a general detector for the target domain in which the robot is deployed, showing also the trade-off between the effort for obtaining new examples from such a setting and the performance gain. In our extensive experimental campaign, we focus on the door detection task (namely recognizing the presence and the traversability of doorways) that, in dynamic settings, is useful to infer the topology of the map. Our findings are validated in a real-world robot deployment, comparing prominent deep-learning models and demonstrating the effectiveness of our approach in practical settings.
The state-of-the-art object detector are subject to critical domain shifts when they are used in robotic application as the standard training datasets largely neglect the noisy, constrained, and challenging operational conditions that a robot faces on the field. In this work, we propose a methodological approach for properly and efficiently adapting these models for service robots. We validate our approach with an extensive experimental campaign on the field with our Giraff-X robot considering a particularly significant perception task: door detection.
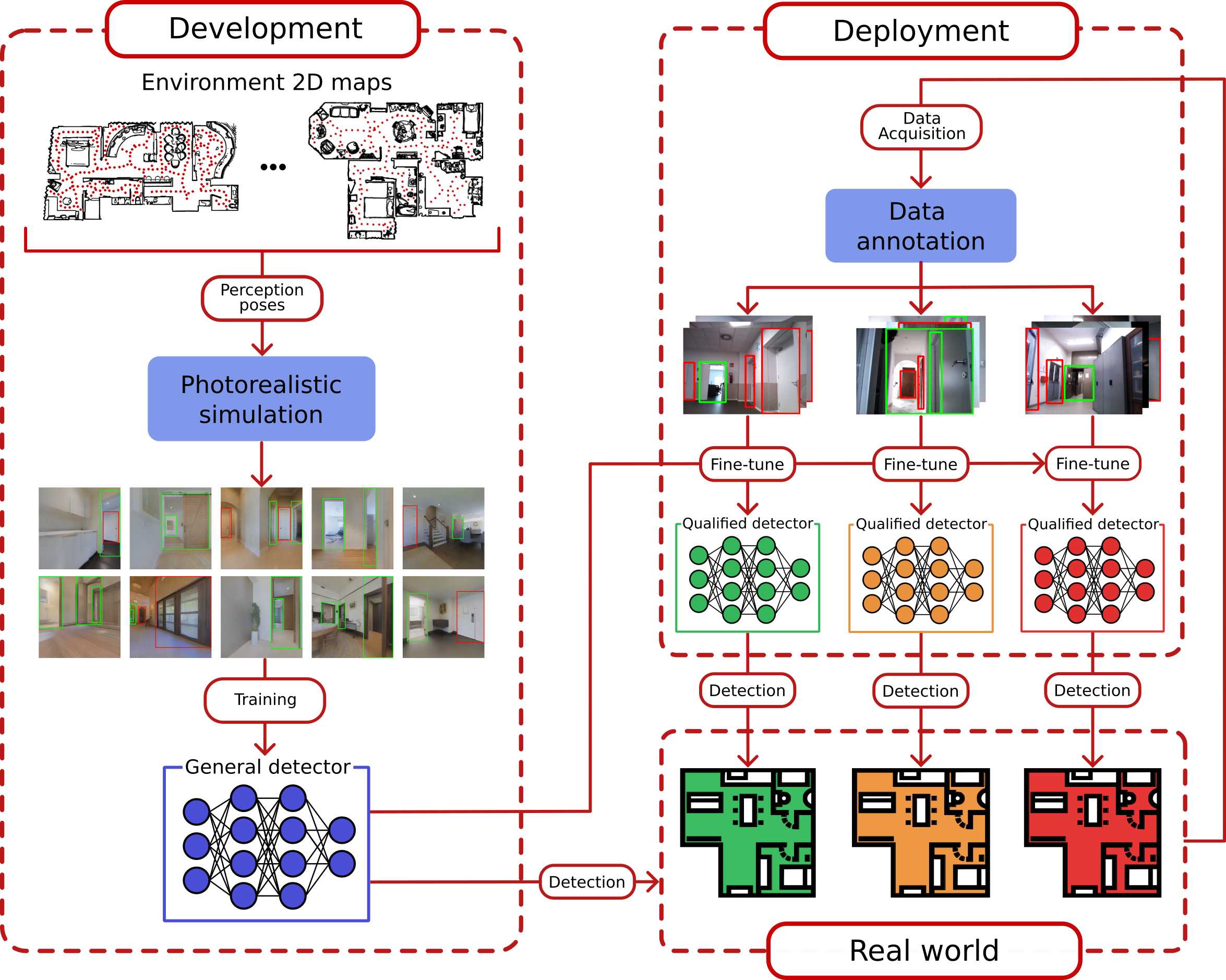
The method we propose is structured around the two principal phases that define the lifecycle of a mobile service robot: the robot’s development phase and the subsequent deployment phase. The development phase for a service robot involves preparing and configuring the platform, including the installation and setup of hardware and software components. The objective here is to setup a robot that is ready to meet the challenges of real-world environments, ensuring vision skills that perform satisfactorily across various environments, thereby ensuring a high level of generalizability. Our approach involves creating a General Detector (GD), designed using utilizing a pose sampling strategy in simulation to develop a photorealistic visual dataset representing typical visual perceptions of a robot.
During the deployment phase, the service robot is introduced for autonomous operation in a target environment, usually for an extended period. This phase often involves a domain shift, presenting challenges to the performance of the previously developed GD. Given the long-term nature of this phase, there is an opportunity to incrementally fine-tune the GD with data collected in the target environment, aligning it more closely with the specific visual features at hand, thus obtaining a Qualified Detector (QD). The process of adapting the detection model to the target environment may require the collection and annotation of data for which we propose a method demonstrating a trade-off between the required effort and the resulting performance improvements.
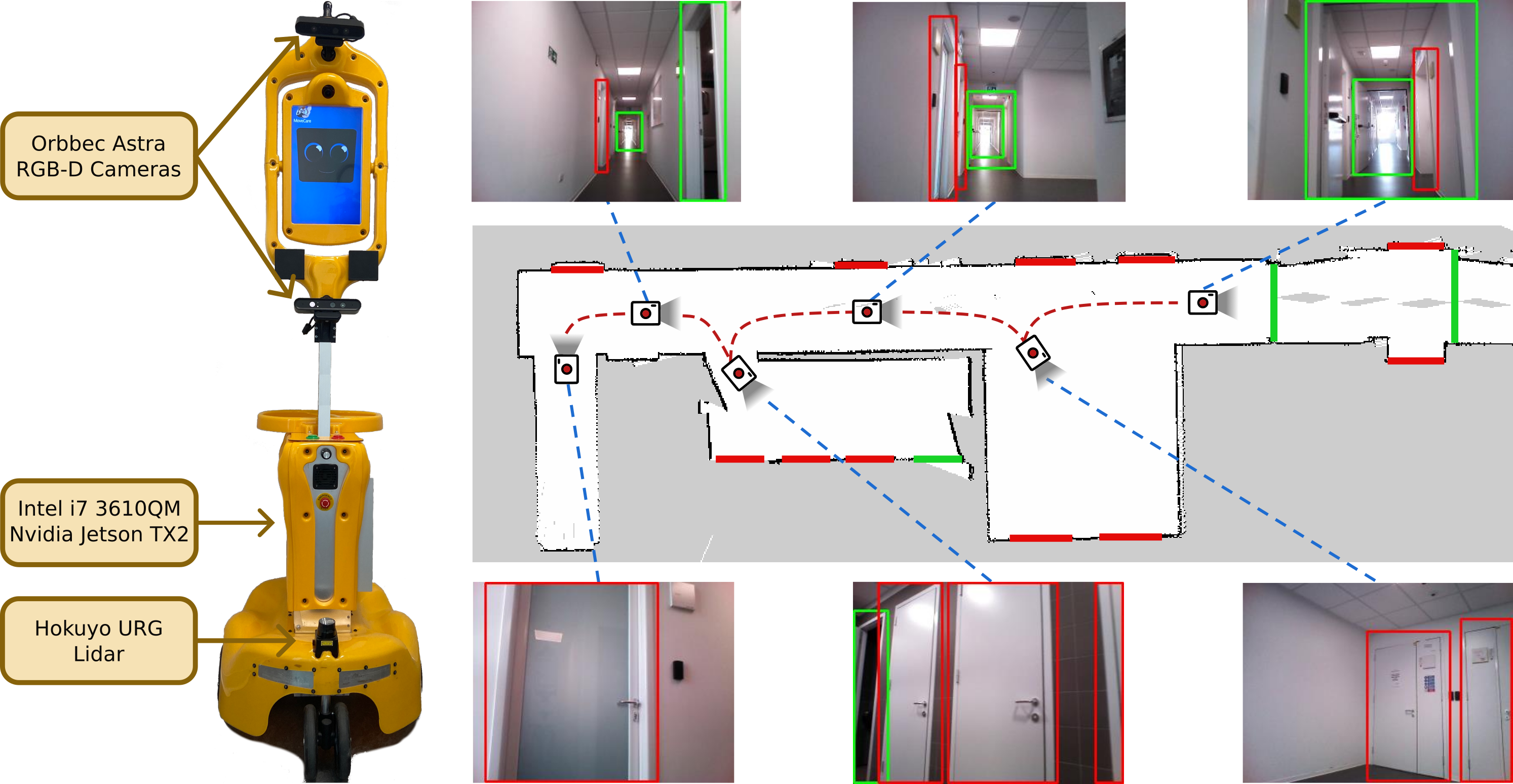
We evaluate the performance of our door detectors with an extensive experimental campaign on th field in which we teleoperate a Giraff-X robot for mapping 4 real environments (3 university facilities and an apartment) while acquiring images at 1 Hz with a low resolution Orbecc Astra Camera. These data compose our \(\mathcal{D}_{\texttt{real}}\) dataset. The full workflow of our method is applied to a significant selection of three prominent deep-earning object detectors: DETR, YOLOv5, and Faster R-CNN.
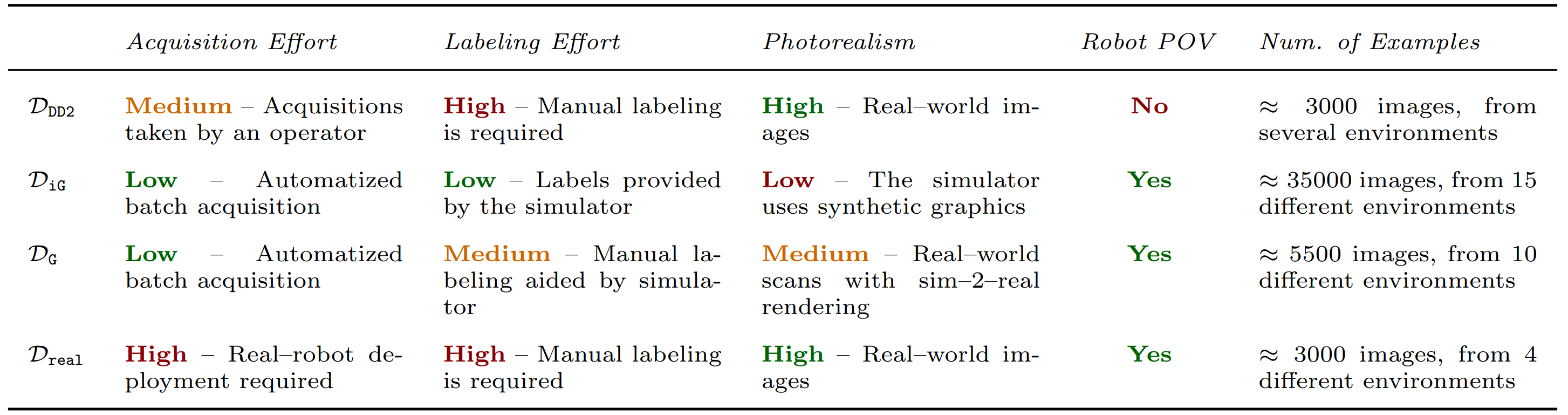
For each object detector, we synthesize four version of general detector using different dataset configurations: \(\mathcal{D}_{\texttt{iG}}\) which is composed of images from a synthetic simulator, \(\mathcal{D}_{\texttt{DD2}}\) containing real images from a publicly available dataset, \(\mathcal{D}_{\texttt{G}}\) is our photorealistic dataset from the robot perspective, and \(\mathcal{D}_{\texttt{DD2+G}}\) is the mixture of \(\mathcal{D}_{\texttt{DD2}}\) and \(\mathcal{D}_{\texttt{G}}\). In the following table, there are reported the characteristics of the datasets.
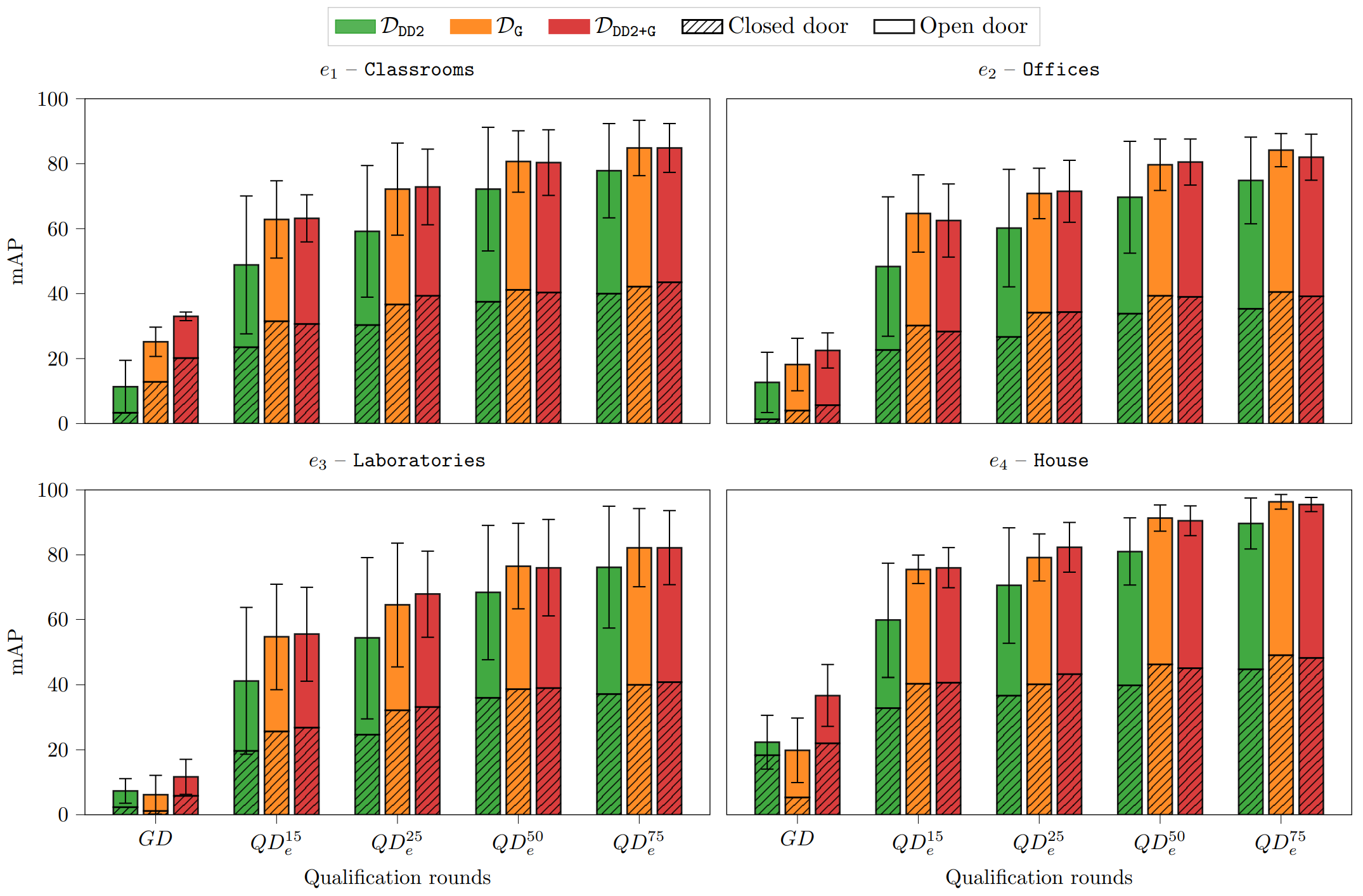
We evaluate the general detectors performance using real world robotic data of \(\mathcal{D}_{\texttt{real}}\). Unsurprisingly, the general detectors trained on \(\mathcal{D}_{\texttt{iG}}\) exhibit very poor performance due to its lack of photorealism. An interesting and perhaps counter-intuitive observation is that our dataset \(\mathcal{D}_{\texttt{G}}\) obtains better performances in certain configuration when compared with \(\mathcal{D}_{\texttt{DD2}}\), which is composed of real-world data. Moreover, the results show that \(\mathcal{D}_{\texttt{DD2+G}}\) obtains the better performance in real world settings using all the reference object detectors, demonstrating that the robot perspective (from our dataset) is important for the model generalization in robotic applications.
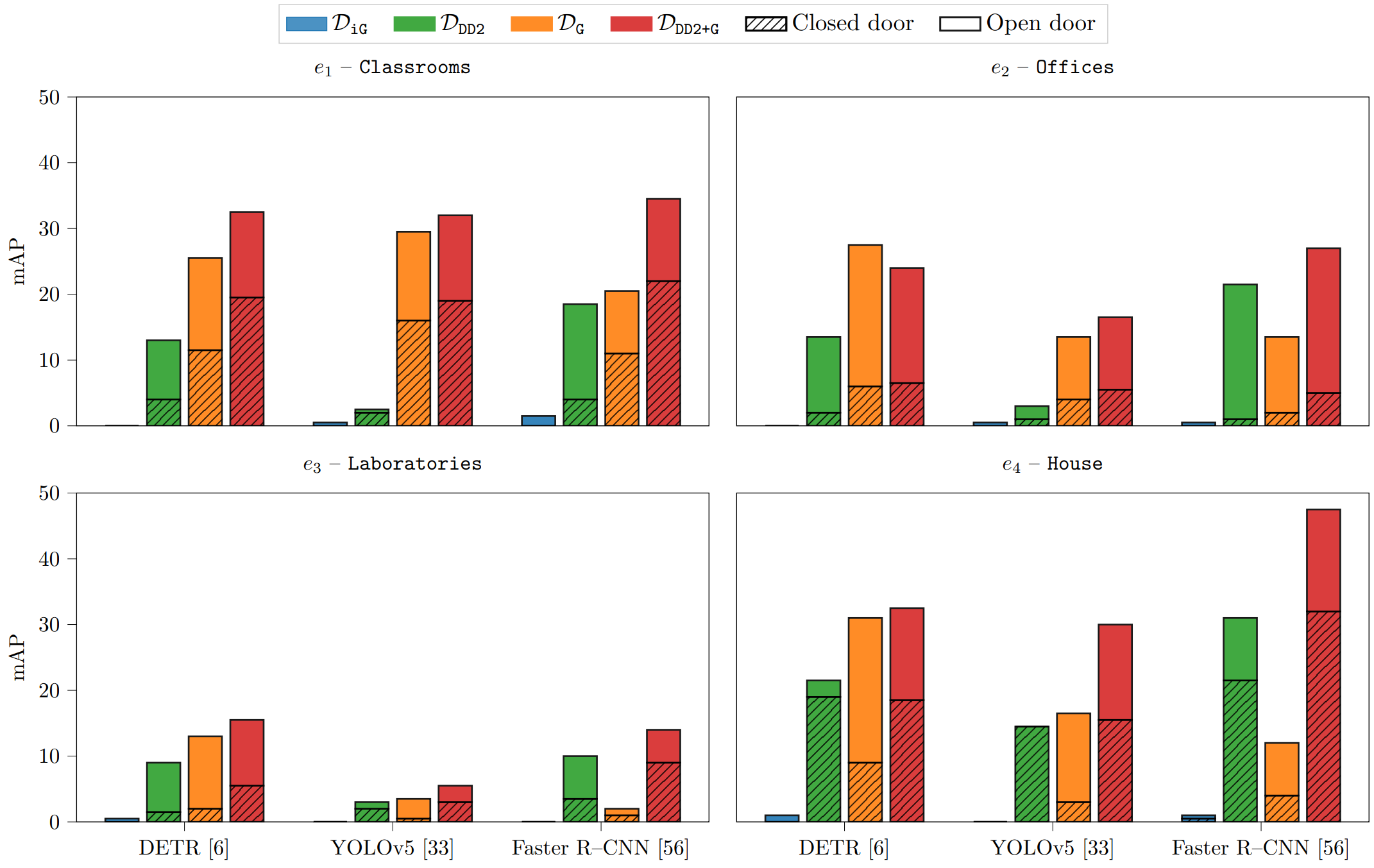

Then, we assess the benefits to general detectors introduced by the qualification procedure by performing 4 qualification rounds with increasing amounts of data for each environment of \(\mathcal{D}_{\texttt{real}}\), thus obtaining \(QD_{e}^{15}\), \(QD_{e}^{25}\), \(QD_{e}^{50}\), \(QD_{e}^{75}\). A first evident observation is that the qualification procedure boosts the performance of the general detectors for the target environment and, unsurprisingly, the performance (together with the data preparation costs) increases as more samples are included, from \(QD_{e}^{15}\) to \(QD_{e}^{75}\). However, the increments follow a diminishing-returns trend, with large gains in the first qualification rounds and marginal ones as more data are used. From a practical perspective, this observation suggests how just a coarse visual inspection of the target environment might be enough to obtain an environment-specific detector whose performance is significantly better than the corresponding general one. It is also important to notice that the dataset chosen to train the general detector does affect the benefits of the qualification. The trends observed in the plots indicate that QDs based on \(\mathcal{D}_{\texttt{DD2}}\) generally demonstrate lower performance compared to those based on \(\mathcal{D}_{\texttt{DG}}\) and \(\mathcal{D}_{\texttt{DD2+G}}\).

@INPROCEEDINGS{antonazzi2023doordetection,
author={Antonazzi, Michele and Luperto, Matteo and Basilico, Nicola and Borghese, N. Alberto},
booktitle={2023 European Conference on Mobile Robots (ECMR)},
title={Enhancing Door-Status Detection for Autonomous Mobile Robots During Environment-Specific Operational Use},
year={2023},
pages={1-8},
doi={10.1109/ECMR59166.2023.10256289}}
}
@misc{antonazzi2024roboticvision,
title={Development and Adaptation of Robotic Vision in the Real-World: the Challenge of Door Detection},
author={Michele Antonazzi and Matteo Luperto and N. Alberto Borghese and Nicola Basilico},
year={2024},
eprint={2401.17996},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2401.17996},
}